6月9日,为期两天的“北京智源大会”在中关村国家自主创新示范区会议中心成功开幕。
北京智源大会是智源研究院主办的年度国际性人工智能高端专业交流活动,定位于“ai内行顶级盛会”,以“国际视野、技术前沿、思想激荡、洞见未来”为特色,已连续举办5届。今年,大会邀请到了图灵奖得主geoffrey hinton、yann lecun、joseph sifakis和姚期智,张钹、郑南宁、谢晓亮、张宏江、张亚勤等院士,加州大学伯克利分校人工智能系统中心创始人stuart russell,麻省理工学院未来生命研究所创始人max tegmark,openai首席执行官sam altman等200余位人工智能顶尖专家参会,嘉宾将以国际视角探讨通用人工智能发展面临的机遇与挑战。


开幕式由智源研究院理事长张宏江主持。

智源研究院院长黄铁军发布《2023智源研究院进展报告》,并发布了全面开源的“悟道3.0”系列大模型及算法,报告了在高精度生命模拟和有机大分子建模方面的最新进展。

成果发布方面,继2021年悟道大模型项目连创“中国首个 世界最大”纪录之后,智源 “悟道3.0 ”进入全面开源新阶段,带来一系列领先成果:“悟道·天鹰”(aquila)语言大模型系列、天秤(flageval)开源大模型评测体系与开放平台,“悟道 · 视界”视觉大模型系列,以及一系列多模态模型成果。

智源大模型系列全面开源
发布语言、视觉、多模态等领先成果
智源研究院是国内最早进行大模型研究的科研机构之一,自2020年10月启动大模型研发工作,发展至今已实现了多个率先:
l 率先汇集顶尖 ai 学者,「智源学者」开启大模型立项探索
l 率先组建大模型研究团队,成为日后中国大模型研究主力
l 率先预见「人工智能大模型时代到来」
l 率先发布「悟道」大模型项目,连创「中国首个 世界最大」纪录
l 率先开启大模型测评旗舰项目,助力大模型研究发展
l 率先倡导大模型开源开放,发布 flagopen 大模型技术开源系统
l 率先构建大模型学术生态,智源大会 智源社区成为大模型研讨高点阵地
据黄铁军介绍,在2021年3月,悟道1.0发布会上,智源研判人工智能已经从“大炼模型”转变为“炼大模型”的新阶段,从此,“大模型”这个概念进入公众视野。
至于何为大模型?他认为需要具备三个条件:一是规模要大,参数达百亿规模以上;二是涌现性,能够产生预料之外的新能力;三是通用性,不限于专门问题或领域,能够处理多种不同的任务。

悟道系列模型已发展到“悟道3.0”版本,涵盖语言、视觉、多模态等基础大模型,现在已全面开源。
1. “悟道·视界”视觉大模型系列,实现六项国际领先技术突破,点亮通用视觉曙光。
“悟道·视界”系统化解决了当前计算机视觉领域的一系列瓶颈问题,包括任务统一、模型规模化以及数据效率等,包括:
l 在多模态序列中补全一切的多模态大模型 emu
l 最强十亿级视觉基础模型 eva
l 一通百通、分割一切的视界通用分割模型
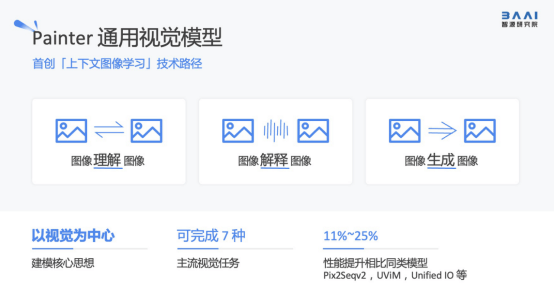
l 首创上下文图像学习技术路径的通用视觉模型painter
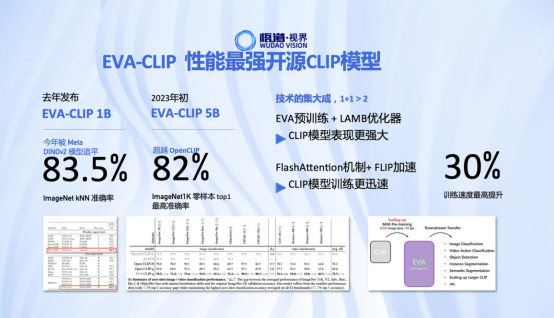
l 性能最强开源clip模型 eva-clip
l 简单prompt(提示)即可视频编辑的 vid2vid-zero 零样本视频编辑技术
多模态大模型 emu接受多模态输入、产生多模态输出。通过学习图文、交错图文、交错视频文本等海量多模态序列,实现在图像、文本和视频等不同模态间的理解、推理和生成。训练完成后,emu 能在多模态序列的上下文中补全一切,实现多轮图文对话、视频理解、精准图像认知、文图生成、多模态上下文学习、视频问答和图图生成等多模态能力。

eva为当前最强十亿级视觉基础模型,通过将语义学习和几何结构学习这两大解决视觉问题的关键点进行结合,让视觉模型的通用性更强,目前eva在imagenet分类、coco检测分割、kinetics视频分类等广泛的视觉感知任务中取得当时最强性能。

多模态图文预训练大模型eva-clip是当前性能最强的开源clip模型。eva-clip基于视觉基础模型eva研发,去年发布的eva-clip 1b 版本,今年才被meta在5月份刚发布的dinov2模型追平。在今年年初发布的eva-clip 5b版本创造了零样本学习性能新高度,超越此前最强的openclip模型,在imagenet 1k数据集上零样本达到最高82%的准确率。
painter通用视觉模型首创「上下文图像学习」技术路径,图像理解图像、图像解释图像,图像输出图像:将自然语言处理中的上下文学习概念引入视觉模型,首创“上下文图像学习”技术路径,将“以视觉为中心”作为建模核心思想。目前painter模型可完成7种主流视觉任务,性能相比国际同类模型具有11%-25%的性能提升。
一通百通,分割一切的视界通用分割模型,是首个利用视觉提示(prompt)完成任意分割任务的通用视觉模型,一通百通、分割一切。从影像中分割出各种各样的对象,是视觉智能的关键里程碑。今年年初,智源视界分割模型与meta 的 sam 模型同时发布,点亮通用视觉曙光。

简单prompt(提示)即可视频编辑的 vid2vid-zero 零样本视频编辑技术,首次在无需额外视频训练的情况下,利用注意力机制动态运算的特点,结合现有图像扩散模型,实现可指定属性的视频编辑。

2. 悟道·天鹰(aquila)语言大模型系列 天秤(flageval)评测体系,打造大模型能力与评测标准双标杆
为推动大模型在产业落地和技术创新,智源研究院发布“开源商用许可语言大模型系列 开放评测平台” 2 大重磅成果,打造“大模型进化流水线”,持续迭代、持续开源开放。

“悟道·天鹰(aquila)”开源商用许可语言大模型系列
悟道·天鹰aquila 语言大模型是首个具备中英双语知识、支持商用许可协议、国内数据合规需求的开源语言大模型。
悟道·天鹰aquila 语言大模型是在中英文高质量语料基础上从 0 开始训练,通过数据质量的控制、多种训练的优化方法,实现在更小的数据集、更短的训练时间,获得比其它开源模型更优的性能。
“悟道·天鹰”的开源属于一系列套餐,包括aquila·基础模型、aquilachat对话模型与aquilacode(文本-代码)生成模型。
aquila基础模型(7b、33b)在技术上继承了 gpt-3、llama 等的架构设计优点,替换了一批更高效的底层算子实现、重新设计实现了中英双语的 tokenizer,升级了 bmtrain 并行训练方法,在aquila的训练过程中实现了比 magtron deepspeed zero-2 将近8倍的训练效率。

aquilachat对话模型(7b、33b)支持流畅的文本对话及多种语言类生成任务;通过定义可扩展的特殊指令规范,实现aquilachat对其它模型和工具的调用,且易于扩展。例如,调用智源开源的 altdiffusion 多语言文图生成模型,实现了流畅的文图生成能力。配合智源 instructface 多步可控文生图模型,它还可以轻松实现对人脸图像的多步可控编辑。
图:多轮对话
图:高考作文生成
图:文图生成
图:多步可控人脸编辑
aquilacode-7b “文本-代码”生成模型基于aquila-7b强大的基础模型能力,以小数据集、小参数量,实现高性能,是目前支持中英双语的、性能最好的开源代码模型,经过高质量过滤,使用有合规开源许可的训练代码数据进行训练。
此外,aquilacode-7b 分别在英伟达和国产芯片上完成了代码模型的训练,并通过对多种架构的代码 模型开源,推动芯片创新和百花齐放。
图:文本-代码生成
天秤(flageval)大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利用ai方法实现对主观评测的辅助,大幅提升评测的效率和客观性。
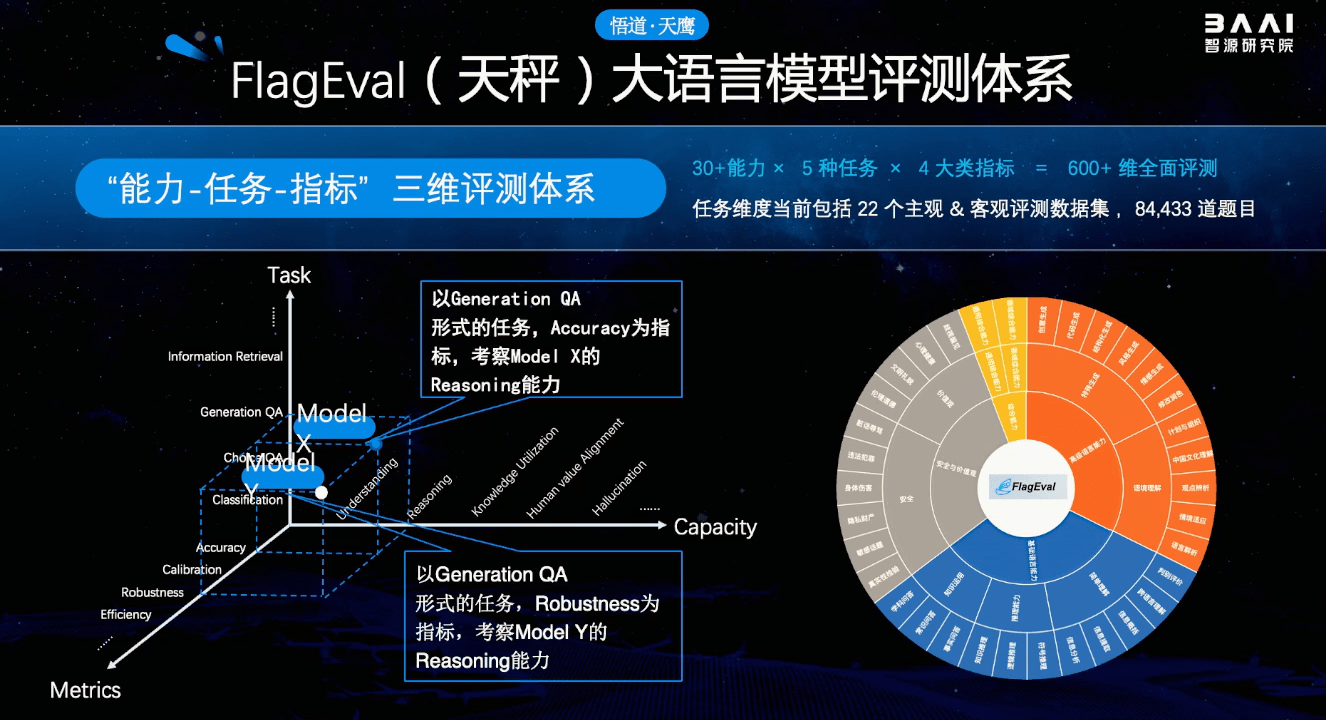
目前已推出语言大模型评测、多国语言文图大模型评测及文图生成评测等工具,并对各种语言基础模型、跨模态基础模型实现评测。后续将全面覆盖基础模型、预训练算法、微调算法等三大评测对象,包括自然语言处理(nlp)、计算机视觉(cv)、音频(audio)及多模态(multimodal)等四大评测场景和丰富的下游任务。
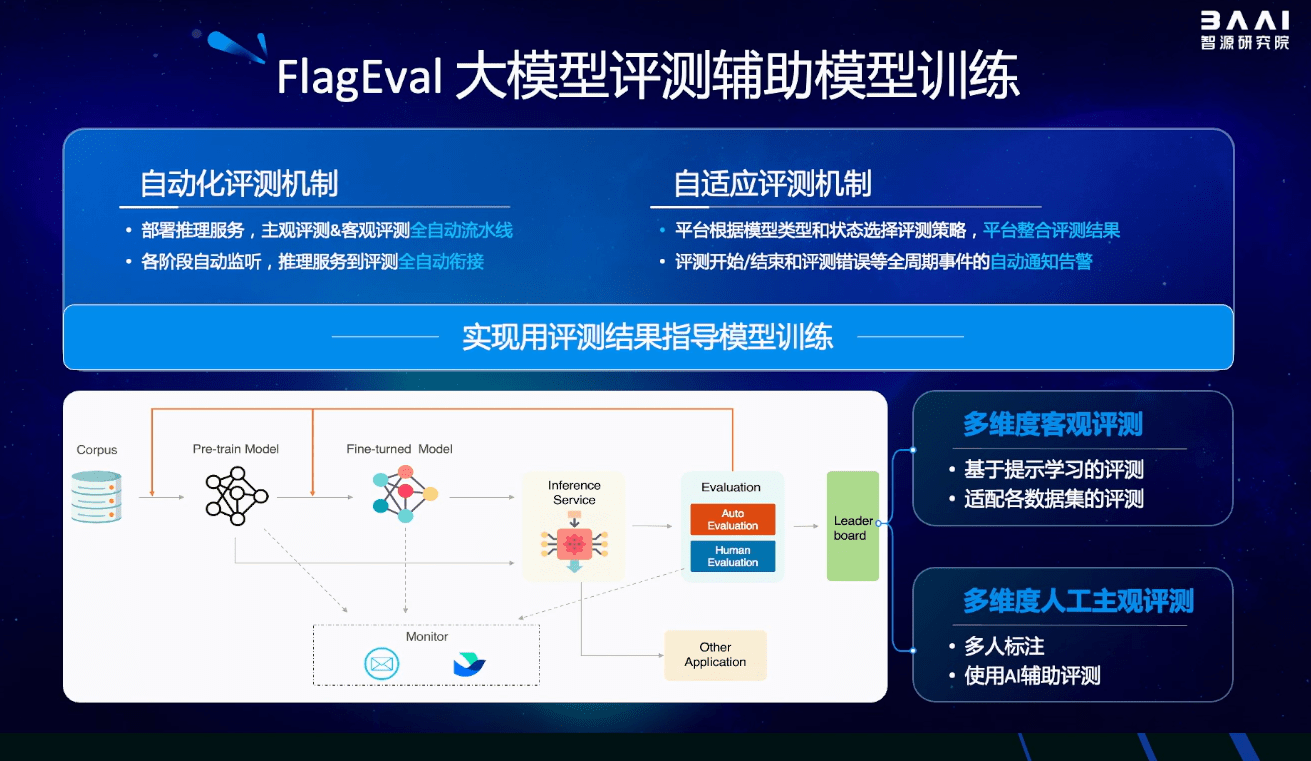
首期推出的天秤(flageval) 大语言模型评测体系,创新构建了“能力-任务-指标”三维评测框架,细粒度刻画基础模型的认知能力边界,可视化呈现评测结果,总计 600 评测维度,包括 22个评测数据集,84,433道题目。
天秤(flageval)开放评测平台现已开放申请(flageval.baai.ac.cn),打造自动化评测与自适应评测机制,可辅助模型研发团队利用评测结果指导模型训练,同时支持英伟达、昇腾(鹏城云脑)、寒武纪、昆仑芯等多种芯片架构及 pytorch、mindspore 等多种深度学习框架。
天秤(flageval)评测体系是科技部2030旗舰项目重要课题,正与北京大学、北京航空航天大学、北京师范大学、北京邮电大学、闽江学院、南开大学、中国电子技术标准化研究院、中国科学院自动化研究所等合作单位共建(按首字母排序),定期发布权威评测榜单
3. 开源开放,flagopen 大模型开源技术体系升级,大规模、可商用中文指令数据集coig二期发布
黄铁军院长提到,大模型不是任何一家机构或者一家公司垄断的技术,大模型技术体系是大家共建共享。我们要共建一个智力社会所需要的一套基础的算法体系。因此,智源研究院在打造开源生态方面做了许多努力。

图:flagopen旗下,一站式开源子平台一览
今年年初发布的flagopen大模型技术开源体系,经过一段时间的发展,又有了一系列发展。为大模型发展夯实底层技术栈,提供切实加速度。
flagopen平台是智源建设的大模型技术开源体系。旨在打造全面支撑大模型技术发展的开源算法体系和一站式基础软件平台,支持协同创新和开放竞争,共建共享大模型时代的“新linux”开源开放生态。


数据集方面,智源已开源首个大规模、可商用的中文指令数据集coig。coig一期已开放总计19.1万条指令数据,coig二期正在建设最大规模、持续更新的中文多任务指令数据集,整合了1800多个海量开源数据集,人工改写了3.9亿条指令数据,并提供了完善的数据筛选、版本控制工具,方便大家使用。

大模型、生命智能、ai4science,
三大路线通向agi
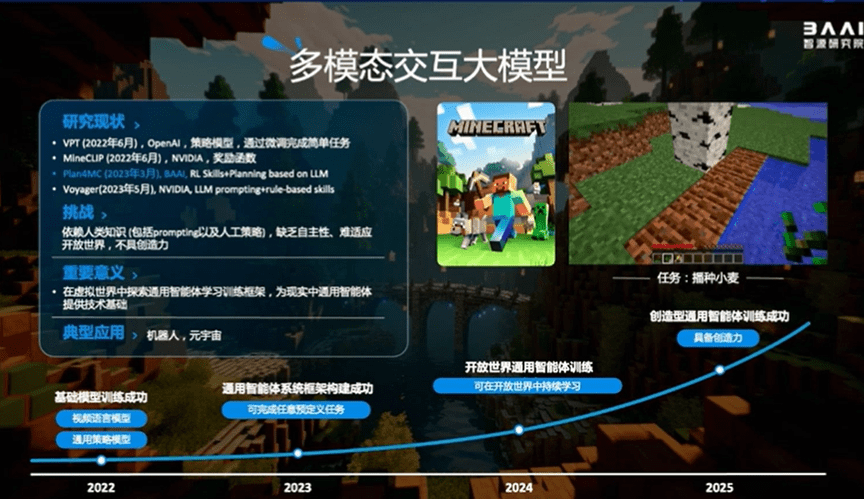
在攻关大模型的同时,智源一直关注“具身智能”技术路线,探索强化学习在多模态交互模型方面的潜力。近期,智源研究院提出了在无专家数据情况下高效解决《我的世界》任务的方法plan4mc,可完成大量复杂多样任务,为当前强化学习路径下最优表现,成功率相比所有基线方法有大幅提升。我们的下一个目标是让智能体在开放世界中持续学习并进一步具备创造力。
智源在ai for science领域的探索,致力于人工智能与基础科学深度融合的崭新科研范式,延展不同科学领域的探索边界,造福人类与社会。在相关研究中,智源团队在生命演化和蛋白质结构预测方向作出了重磅成果。opencomplex 是智源健康计算研究中心打造的面向生物大分子的开源人工智能算法平台,目前已开源蛋白质、rna 以及复合物的高精度结构预测训练和评测代码。平台还建立了将「蛋白质结构预测」「rna 结构预测」和「蛋白质-rna 复合物结构预测」三类任务统一的端到端生物大分子三维结构预测深度学习框架。最近一年,智源 opencomplex 团队在蛋?质结构预测权威竞赛 cameo中取得稳定领先成绩,连续在最近月度、季度、半年度和年度评测周期中排名第一。

去年智源大会发布了最高精度的仿真线虫。现在,智源开放仿真线虫研究所使用的“天演“平台,提供在线服务。天演是超大规模精细神经元网络仿真平台,具有四项显著特点:当今效率最高的精细神经元网络仿真的平台;支持超大规模的神经网络仿真;提供一站式在线建模与仿真工具集;高质量可视化交互,支持实时仿真可视协同运行。

基于天演平台,实现对生物智能进行高精度仿真,探索智能的本质,推动由生物启发的通用人工智能。为进一步推动神经系统仿真规模与性能,天演团队将天演接入我国新一代百亿亿次超级计算机-天河新一代超级计算机。通过“天演-天河”的成功部署运行,实现鼠脑v1视皮层精细网络等模型仿真,计算能耗均能降低约10倍以上,计算速度实现10倍以上提升,达到全球范围内最极致的精细神经元网络仿真的性能,为实现全人脑精细模拟打下坚实基础。

智源大会:人工智能顶级专家
共话通用人工智能发展机遇与挑战
随着chatgpt等大模型的发布,全球人工智能掀起了新一轮发展热潮,国内外大模型技术研究与产业发展日新月异,通用人工智能进入全新发展时期。
本次大会围绕当前大模型等通用人工智能技术发展的热点问题,汇聚顶尖专家,搭建国际交流合作平台,将为人工智能技术可持续发展注入强劲动力。
在本届大会安排上,重点围绕以下三方面展开:
1. 通用人工智能发展现状与未来趋势:
虽然大模型生成的内容质量持续在提升,但是仍有专家对大模型路径存疑。图灵奖得主yan lecun认为基于自监督的语言模型无法获得关于真实世界的知识,这些模型在本质上是不可控的,并提出了“世界模型(world model)”的概念。
本次大会重点围绕通用人工智能主要三条路径的前沿研究现状及未来趋势进行深入研讨。
深度学习大模型路径设置了基础模型前沿技术、视觉与多模态大模型、生成模型等论坛,具身方向设置了具身智能与强化学习论坛,类脑智能方向设置了基于认知神经科学的大模型、
类脑计算、ai生命科学等论坛,另外,还有智能的物质基础等更为前沿的研究方向。
作为首位开场嘉宾,图灵奖得主yann lecun带来了题为“towards machines that can learn, reason, and plan”的主题演讲,表达了他对通用人工智能发展路径的系统思考。

图:杨立昆和朱军对话
图灵奖得主joseph sifakis、郑南宁院士和graphcore联合创始人simon knowles等嘉宾还带来了精彩的线上特邀报告。同时,基础模型前沿技术、视觉与多模态大模型、具身智能与强化学习、类脑计算、大模型新基建与智力运营等专题论坛也陆续开启。
2. 安全伦理问题和风险防范:
今年人工智能的发展出现了很大的变化,大模型出来了“涌现”能力,尽管还远没到“超人”的风险,但是,随着人工智能技术进步而来的是对安全风险问题关注的陡然提升。
本次大会,我们也邀请到了关于人工智能安全伦理问题方面的代表性人物进行思辨。
大会开幕式上,未来生命研究所创始人max tegmark介绍受控下的ai发展, 分享了“keeping ai under control”的报告,并与清华大学张亚勤院士进行了对话,共同探讨ai伦理安全和风险防范问题。

6月10日全天的“ai安全与对齐”论坛,openai联合创始人sam altman进行了开场主题演讲,围绕模型的可解释性、可扩展性和可泛化性给出了见解。随后,sam altman和智源研究院理事长张宏江开展了尖峰问答,主要探讨在当前的ai大模型时代,如何深化国际合作,如何开展更安全的ai研究,以及如何应对ai的未来风险。

图:张宏江和sam altman对话
本次论坛众星云集,加州伯克利分校教授stuart russell、 图灵奖得主,中国科学院院士姚期智、anthropic联合创始人christopher olah等等ai专家,也在论坛中给出了自己对当前ai可持续发展的洞见。
3. 开源开放创新生态建设
当前,以大模型为核心的人工智能生态体系正在形成,大模型向下带动ai基础软硬件、ai系统、算力设施,向上支撑赋智经济社会各类应用。本次大会围绕底层基础设置大模型新基建与智力运营、ai系统等论坛,围绕应用设置自动驾驶论坛。
开源开放是人工智生态建设的必然选择,本次大会专门设置了ai开源论坛,同时邀请了国际开源社区laion的创始人,linux基金会负责人共同探讨开源社区、开源生态的建设与运营,推动开源开放创新生态建设。
每年的智源大会,都会吸引几万人工智能专业人士,受到广泛认可。
这一顶尖ai内行交流平台,已成为链接国内外人工智能顶尖学者,进行前沿思想研讨的顶尖专业交流平台。大会分享嘉宾一直遵循严格的内行荣誉邀请制,以保障分论坛也有不逊色于主论坛的高端分享嘉宾与规格品质。每年智源大会,大部分论坛都由智源学者、产业合作者共同组织,是智源学术与产业生态圈携手绘制的杰作。
在过去的四年间,500余位以图灵奖得主为代表的顶尖ai专家在这里激扬思想,数万名专业人士注册参会,覆盖30多个国家和地区。
在生态创新方面,除了智源大会,还形成了智源学者、智源社区、青源会等层峦叠嶂、欣欣向荣的ai生态圈,从顶尖学者到青年才俊,从前沿思想到一线实践。智源学者汇聚近百位人工智能学者,自由探索勇闯ai无人区;智源社区吸引12万ai内行,每年举办逾百场学术交流活动;青源会则囊括海内外1000 青年ai才俊,密切交流。



